At ITHAKA, we believe the most meaningful innovation happens when technical exploration and an understanding of the people we serve evolve together. Collaboration across research, engineering, design, and product is standard in how we work. This approach includes continuous research engagement with the communities and users we serve, and technical explorations of emergent technologies. It has long informed the products and services we’ve developed for the higher education community, including JSTOR, Artstor, JSTOR Forum, and now JSTOR Digital Stewardship Services. Sometimes, however, more profound shifts in technology spark novel approaches to collaboration as we aim to adjust our frameworks to account for radically new opportunities that serve our community.
Taking a broader view
We wanted to know not just what was technically possible, but what could be most meaningful to the people doing this work every day, and amplify progress toward institutional goals for their distinctive collections.
When we first began exploring what we could develop with generative AI in service of distinctive collections, we knew we had to find new ways to collaborate. The field of possibilities opened up by this new technology warranted a new approach. Rather than a single collaborative cross-functional product team directed by known community needs and technical capabilities, we needed time and space for engineering to truly explore what this new technology could do. That exploration would need to be both informed by the broadest possible understanding of the archival landscape, and unhampered by a specific product scope or user need.
This didn’t mean that research waited in the wings for the “right time” to engage. It meant we needed to zoom all the way out, and reconsider the biggest challenges and opportunities that may have previously seemed too big or too challenging to undertake. Instead, we set out to define the opportunity: to understand the pain points, ambitions, and constraints facing archivists, librarians, and museum professionals. We wanted to know not just what was technically possible, but what could be most meaningful to the people doing this work every day, and amplify progress toward institutional goals for their distinctive collections. We were on a mission to identify where to direct generative AI to make the greatest impact.
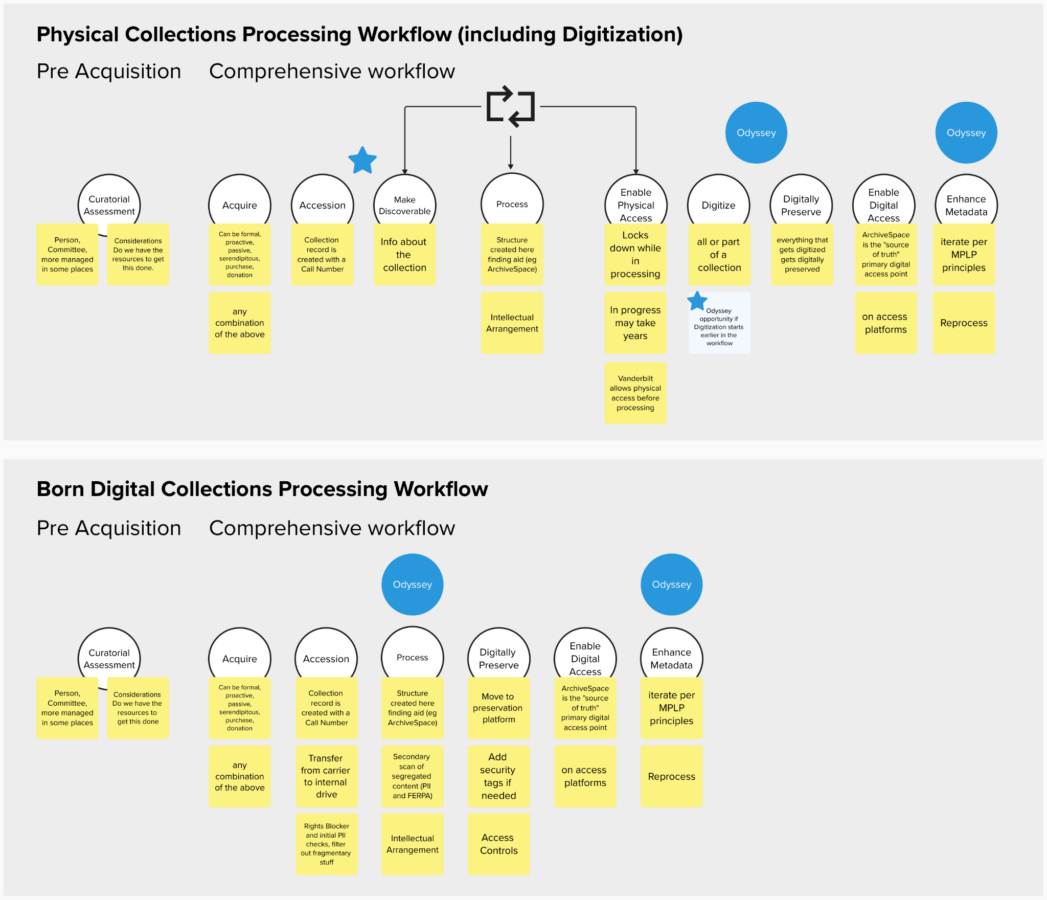
For over a decade, JSTOR has developed tools to support collections stewards, and our decision to focus this exploration on archives and special collections grew out our history with this community. Particularly informative was our research connected to JSTOR Forum, a tool for cataloging and metadata management, originally developed to support visual resources.
Our team was already in sustained conversation with practitioners, as they navigated the day-to-day realities of managing digital collections. Across this work, recurring patterns were already present: collections were becoming more complex and heterogeneous, staff responsibilities were expanding even as resourcing shrank, and the available tools left critical gaps between institutional goals and daily workflows. These signals highlighted needs that were not fully addressed by current systems, and surfaced clear areas for potential intervention with the right technology.
Expanding our knowledge
The research we conducted to explore the potential of AI for archives and special collections included contextual inquiry, landscape analysis, co-creation activities, and concept testing. Led by Jen Saville, these traditional UX research methods were adapted and adjusted to flex with rapidly evolving technical learnings. This research highlighted moments in existing archival workflows that were prime for intervention and support, such as “what’s in the box” and high vs. low cognitive tasks.
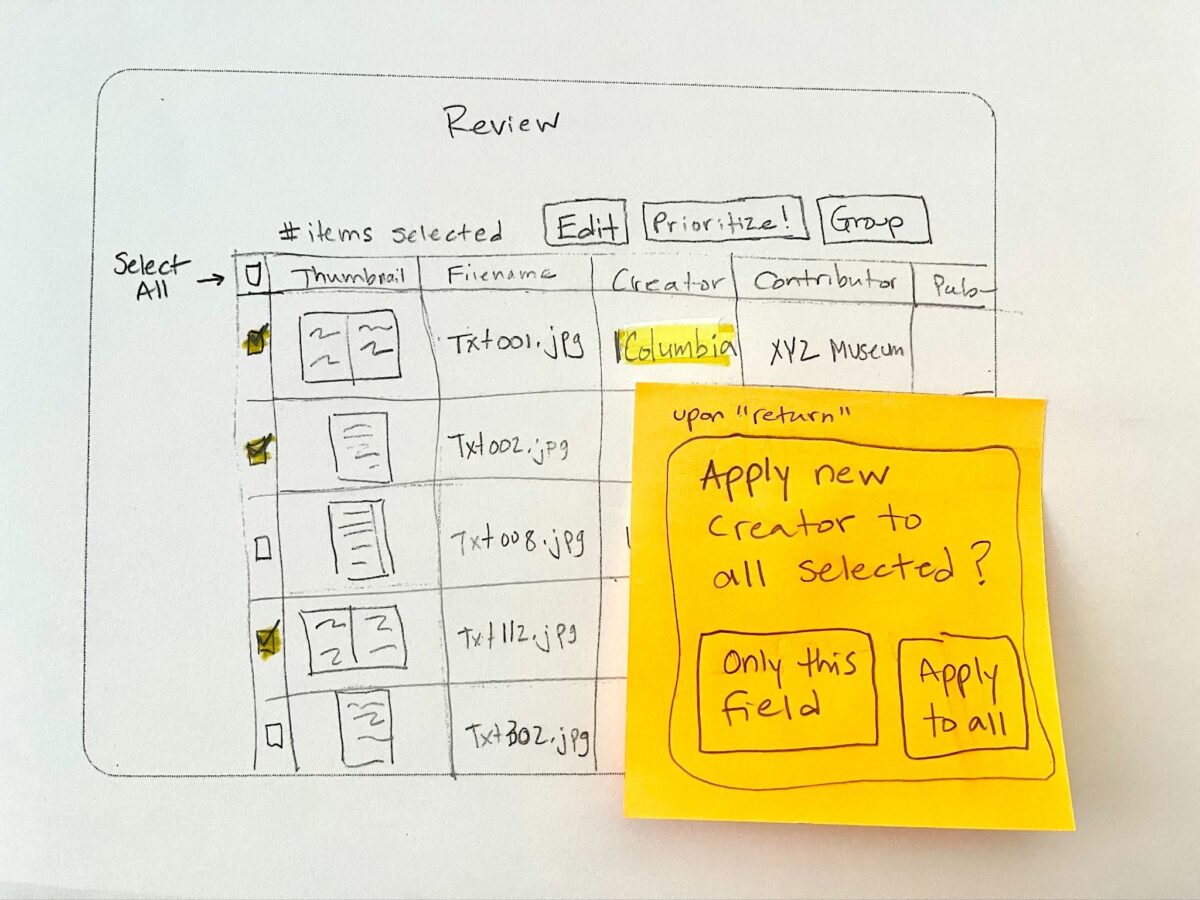
We also expanded the research team to include Emilie Hardman, a subject matter expert in archives, to bring nuance and specificity to this highly complex work. Emilie’s field work resulted in Bridging Capacity and Care: A Field Report on Archives and Special Collections, which synthesizes conversations with approximately 280 archival professionals from 24 institutions in the U.S. and U.K., and surfaces fundamental tensions in contemporary archival work, particularly the balancing act of negotiating between constrained resources, digital transformation, and increased ethical complexity.

Working in parallel, the engineering team rapidly built a proof-of-concept to test whether high-quality descriptive metadata for primary source materials could be generated at scale. Weekly sprints focused on core capabilities: developing evaluation infrastructure, confidence scoring, and human-in-the-loop review workflows; orchestrating LLMs and external APIs; managing data storage; handling varied media types; and standardizing descriptive metadata output in Dublin Core. Once technical feasibility was established, the focus shifted to hardening and operating the system for speed, reliability, and scalability.
Triangulating research and technology
As these technical and environmental tracks came together, they informed each other, and triangulated on the opportunity for a truly transformative solution. We were uniquely positioned to respond to the reality that capacity constraints and processing backlogs often force teams to scale back critical descriptive work in order to make collections minimally available, leaving discoverability uneven and incomplete. At current resourcing, some collections could take decades to fully describe at the level required for digital discovery. This sparked a connection between seemingly insurmountable challenges and emerging technological capabilities: AI-assisted, expert-informed, metadata creation.
The result is JSTOR Seeklight, a first-of-its-kind, AI-driven collections processing tool that empowers institutions to accelerate description and transcription, deepening the impact of their distinctive collections, while keeping archival expertise at the center. JSTOR Seeklight has already evolved beyond its initial scope of metadata generation to digital collections processing, extending its capabilities to address a wider range of community needs, such as supporting Handwritten Text Recognition (HTR) transcripts for a range of handwritten and text based materials.
Continued engagement
As we continue to explore the intersection of human expertise and machine capability, user research serves as critical connective tissue ensuring that emerging technologies stay rooted in real needs, ethical considerations, and meaningful impact.
Our partnerships with libraries, archives, and museums continue to ensure JSTOR Seeklight is not just a technical achievement, but a community-driven one. In addition to the research cycles that drive all of our work at ITHAKA, we are working with a growing community of charter participants with deep, often daily, collaboration to refine and improve JSTOR Seeklight. This is partly why it’s been recognized with honors such as the Anthem Award for Best Use of AI in Education, Art & Culture, and the C.F.W. Coker Award for Description from the Society of American Archivists.
As we continue to explore the intersection of human expertise and machine capability, user research serves as critical connective tissue ensuring that emerging technologies stay rooted in real needs, ethical considerations, and meaningful impact.
At ITHAKA, we see user research not as a step in the process, but as a strategic practice that moves in parallel with engineering and design to drive discovery, innovation, and transformation. Research is not a gate or a sign-off; it’s a continuous input that shapes vision, priorities, and outcomes.
After all, when we understand what people are striving for as deeply as we understand what technology can do, we can build tools that truly extend human capability.