In archival work, digitization tends to get the spotlight. It’s visible, measurable, and relatively straightforward to explain. But for stewards of distinctive collections, the real work—and the real constraint—often comes after, in the detailed description that makes materials discoverable and usable.
This is a challenge we heard consistently across institutions, and one we set out to address collaboratively. JSTOR Seeklight is an AI-assisted tool for metadata generation, transcription, and other key steps of collections processing, shaped by archivists who helped define the problem, test early ideas, and refine the approach.
“Digitizing is really a very short part of the process for us. What becomes incredibly lengthy and labor-intensive is the description of materials.”
–Alexis Braun Marks, University Archivist, Eastern Michigan University (EMU)
Just over a year after launching JSTOR Seeklight, we’ve been reflecting on that collaboration alongside early partners like Alexis Braun Marks, University Archivist at Eastern Michigan University (EMU), who joined us as a beta participant. This collaboration offers a window into what it takes to build technology that genuinely supports the field.
The work behind access
The challenge Alexis and her EMU team faced wasn’t getting materials scanned, but getting them described. As she put it, “Digitizing is really a very short part of the process for us. What becomes incredibly lengthy and labor-intensive is the description of materials.”
That work—creating titles, descriptions, subject terms, and context—is what makes collections discoverable. Without it, digitized materials remain hidden.
“We often have digitized content that might sit for a semester, a year, maybe two before it’s described,” Alexis noted.
One example from the EMU team captures this clearly: a metadata spreadsheet with 67 rows of careful, detailed work that comes to an abrupt stop when a student internship ends. The remaining scans exist, they just haven’t been described.
EMU’s experience is not unusual. As Alexis put it, “This is not uncommon. We are not alone in this as far as archives go.”
Across institutions, backlogs of unprocessed or minimally described materials grow while staffing and budgets remain limited. The result is a persistent gap between not only what exists and what is digitized, but what has been digitized and what can actually be discovered and used.
Metadata is the bridge between those two states, and it’s also where things slow down.

Starting with questions
To explore whether technology could help, my colleagues and I began by asking questions rather than proposing solutions. Through conversations with library leaders at more than 60 institutions, and direct observation of workflows throughout 2024, we sought to understand where technology might actually make a difference.
That work led us to a set of guiding “How might we” questions, or simple, open-ended prompts used in design thinking to explore possibilities before jumping to solutions:
- How might we leverage technology to speed up processing of digital archives and special collections?
- How might we generate descriptive metadata aligned with archival standards and workflows?
- How might we ensure technology assists, but does not replace, human labor?
That last question became a foundation and a guardrail, and it could only be addressed by collaborating closely with the people who do the work.
A partnership rooted in a shared mission
Collaborative and productive research requires common ground, and JSTOR’s mission to expand access to knowledge and education aligns closely with the missions of university libraries and archives.
This shared purpose made it possible to bring together a cohort of institutions interested in solving a common problem.
For EMU, partnership was also practical. As Alexis reflected, “Being able to partner with other organizations…is really the only way that we are able to get work moving forward.”
For smaller archives teams like EMU’s, this kind of cross-institutional collaboration creates space to test ideas, share candid feedback about what works and what doesn’t, and help shape tools that reflect real constraints.
Listening, building, and testing together
Rather than designing in isolation, we spent time with archivists and staff to observe, ask questions, and learn where things slow or break down. We came away with a much clearer picture of the complexity involved, and together, began to see where there were opportunities to help.
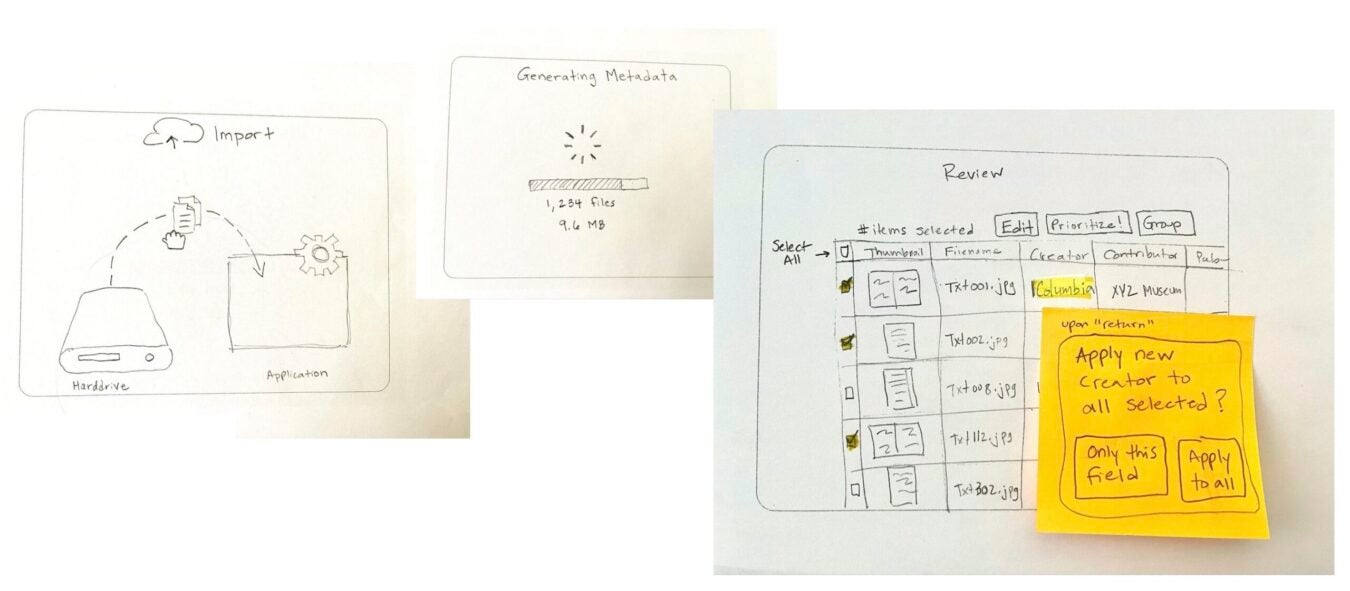
Early product design exploration was intentionally lightweight: paper prototypes, workflow mapping, and conversations that gave archivists something to react to. The goal wasn’t to get everything right upfront, but to understand the work well enough to begin testing ideas together.
By late 2024, we had a working prototype designed to test how AI could support metadata creation within archival workflows—pairing technology with guardrails shaped by archival practice, including metadata schema requirements, controlled vocabularies, and human review.
“Never in this partnership did we feel like we were doing this work for no one but ourselves. The JSTOR team was taking the feedback, improving the tool for future users to use.”
–Alexis Braun Marks
As beta partners, Alexis and her colleagues at EMU were essential to that testing process. They brought sample materials—images, PDFs, and text-based documents—and compared AI-generated metadata against their own standards.
Some outputs were immediately useful. AI-generated titles and descriptions often provided a solid first draft, giving staff a place to start instead of a blank spreadsheet.
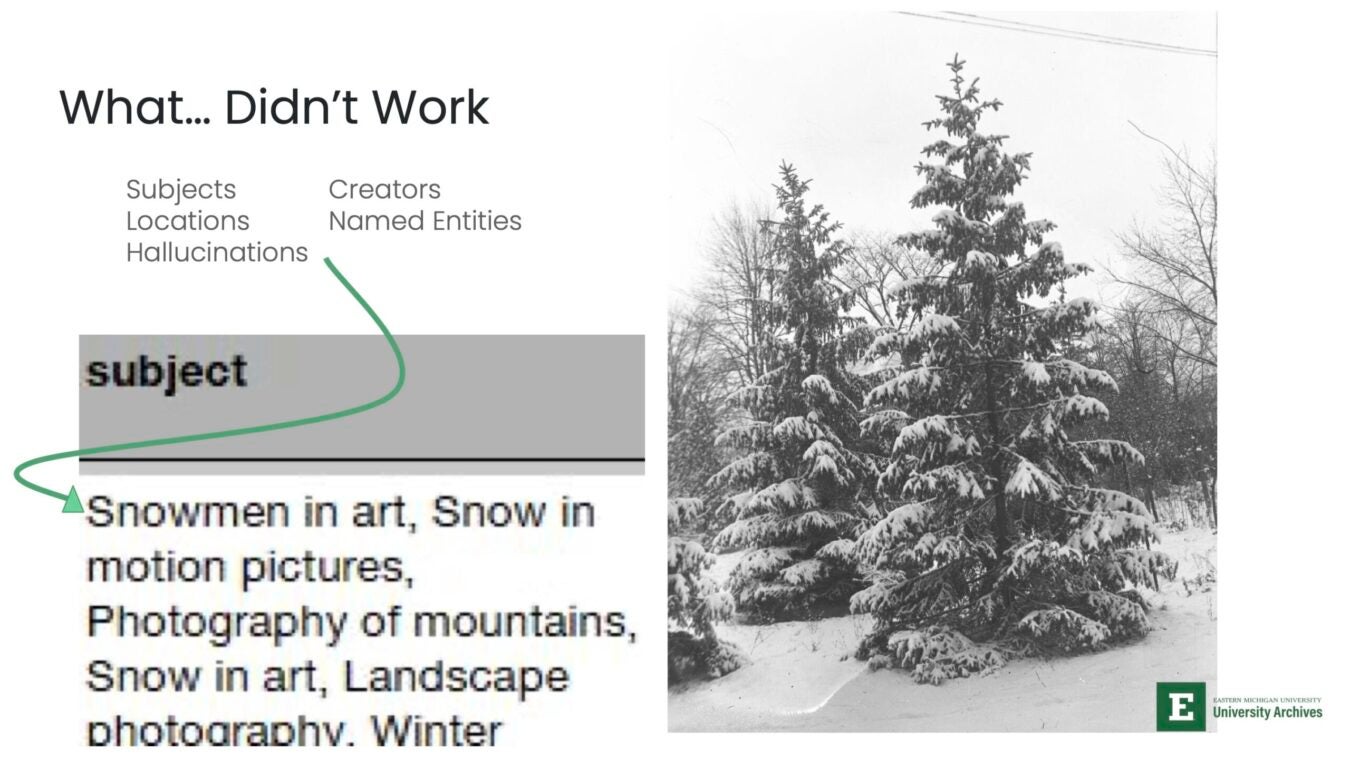
Other results exposed clear limitations. Subject terms could be off or misleading. In one example, an image of a pine tree was tagged with terms like “snowmen” and “art,” a reminder that without context, models can confidently produce the wrong thing.
What emerged was a clearer picture of where AI could help, and where it needed structure. Faster first drafts were valuable, but only when paired with strong review workflows, clear metadata expectations, and limits on how outputs were generated.
This phase wasn’t about getting perfect results, and in some ways, it was the opposite. We needed to expose limits and shortcomings to determine how to apply the right guardrails for supporting real archival work.
The feedback loop
What made the beta extra meaningful was the feedback loop.
EMU and other beta partners reviewed outputs, flagged issues, and explained why something didn’t meet archival standards—where subject terms drifted, context was missing, and descriptions needed to be constrained.
JSTOR took that feedback, adjusted the approach, and brought updated results back to the team to review again. Then the process repeated.
Over time, that design, build, test, learn cycle helped shape a tool that aligned more closely with real archival practice. This wasn’t accomplished by getting everything right at once, but by iterating with the people doing the work.
This also produced something less tangible but just as important. As Alexis reflected, “Never in this partnership did we feel like we were doing this work for no one but ourselves. The JSTOR team was taking the feedback, improving the tool for future users to use.”
Instead of a tool being developed top-down and released to the field, it was shaped through ongoing use, critique, and refinement. This reflects JSTOR’s approach to product development more broadly: partnering with the community, testing and adjusting based on feedback, and improving over time.

From prototypes to JSTOR Seeklight
Our collaboration with EMU and other beta partners directly shaped what is now JSTOR Seeklight, the collections processing tool within JSTOR Digital Stewardship Services. The tool focuses on the areas where institutions saw the most value: metadata generation and transcription, with human review at the center.
By embedding the tool within the JSTOR Stewardship platform, which brings together the core parts of digital stewardship—processing, management, preservation, and access—we integrated it into a workflow that aligns with how institutions actually work:
- Uploading and organizing materials
- Generating metadata and transcripts
- Reviewing and editing outputs
- Tracking progress across collections
- Sharing and preserving materials for long-term access
Guardrails developed during testing remain central. Institutions retain control over their data, outputs are easy to review, and context, which AI cannot generate on its own, comes from the archivists themselves.

Ethics, labor, and institutional reality
Archival work is labor: It requires interpretation, context, and care.
By collaborating directly with archivists like Alexis, we worked to not remove that labor, but rethink it. Instead of starting from a blank spreadsheet, archival staff can begin with a draft, shifting effort toward reviewing, questioning, and finessing metadata.
That changes the nature of the work, including for student workers that are an essential part of many archives’ staffs, including EMU. Students aren’t just generating metadata, they’re learning how to evaluate it, deciding what’s accurate, what’s missing, and what needs to be clarified.
It also changes how institutions think about training. The focus shifts from entering data to reading records critically, and applying standards with intention.
At the same time, the constraints are real. Budgets are limited, staff capacity is stretched, and any new tool has to fit into workflows that already exist.
That means using AI where it helps, keeping human judgment at the center, and ensuring the work remains intentional and grounded, not just a faster way to get through it.
What this suggests for the field
What this work points to is less about a single tool and more about a way of working.
Start with real workflows. Test ideas in context. Pay close attention to where things break down. Then come back with something better, and test it again.
That’s what Alexis, the team at EMU, and our community of beta testers helped make visible. Beyond efficiency gains, the value that emerged was in shifting effort toward the parts of the work that require judgment—reading closely, adding context, and deciding what’s actually accurate.
It also shows what it takes for this kind of technology to be useful in practice: shared purpose, close collaboration, hands-on experience, and guardrails shaped by the field, not added later.
For archives and special collections, this approach matters. It keeps expertise at the center, and creates a path for new tools to fit into the work without reshaping it in ways that don’t hold up.
Seen this way, JSTOR Seeklight is part of an ongoing process, continuously iterated on through collaboration with the people doing the work.
Interested in shaping the future of AI-assisted stewardship? Learn more about JSTOR Digital Stewardship Services.